执行性能
虽然HybridCLR也是解释执行,但无论从理论原理还是真机测试数据表明,HybridCLR相比当前流行的lua、ILRuntime之类的热更新方案,性能有极大的提升(数倍甚至数十倍)。
测试报告
HybridCLR是目前性能最高的CLR解释器实现,也是当前所有热更新方案中性能最优异的,综合性能超出其他方案一个数量级以上。
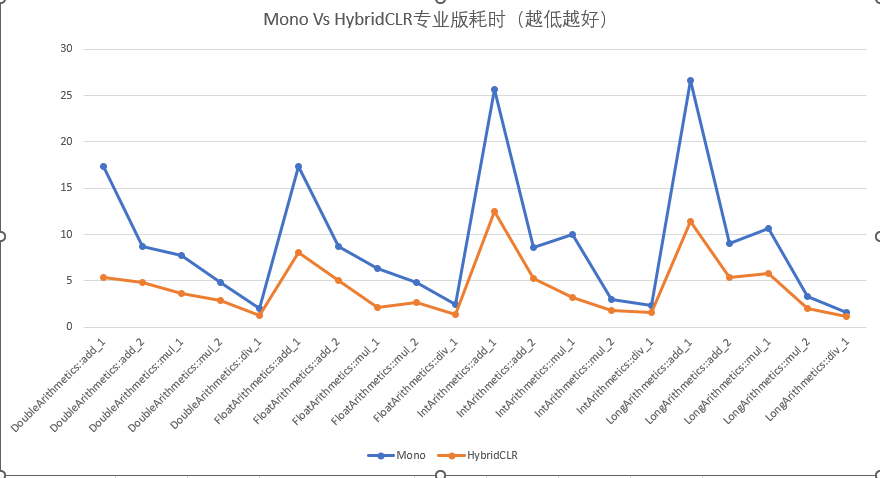
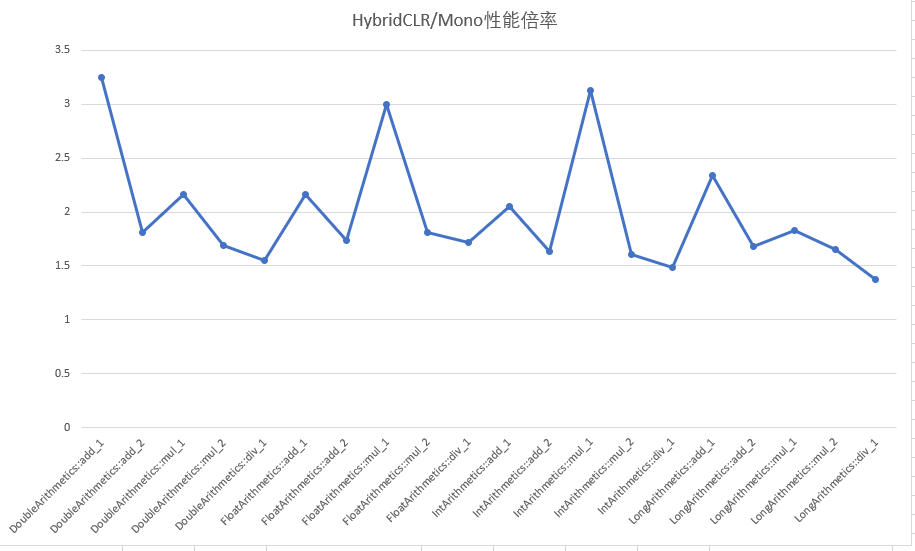
HybridCLR商业化版本的综合性能大幅优于Mono的mint实现,数值计算指令性能是Mono的140%-330%之间。
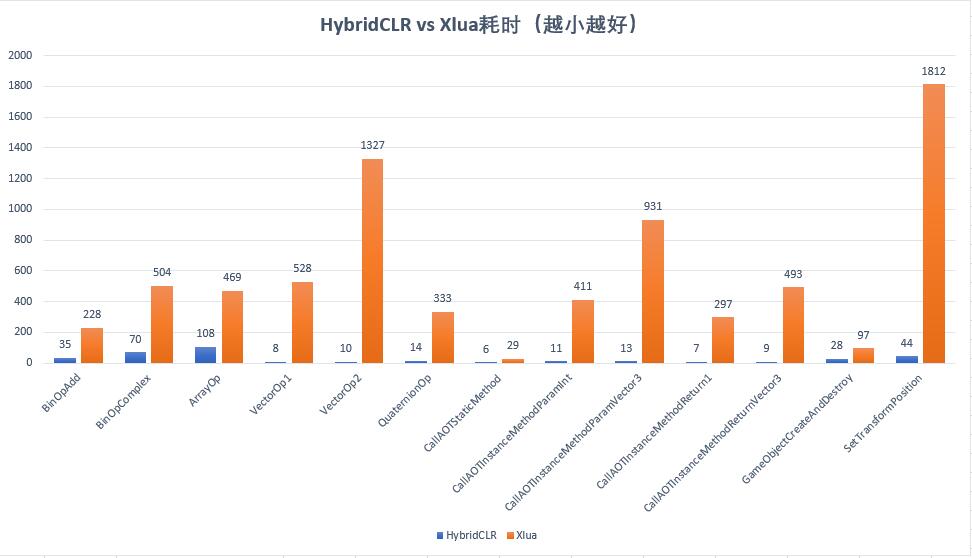
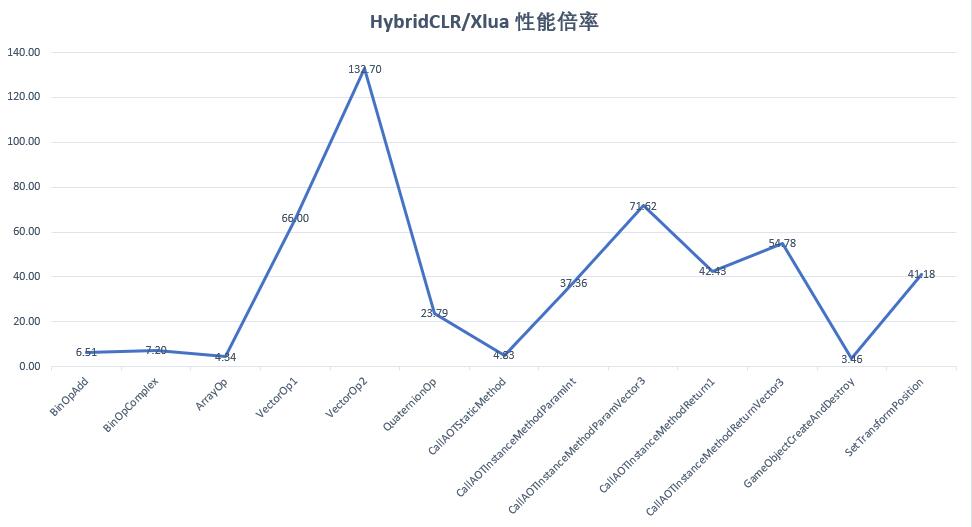
HybridCLR商业化版本的性能全面碾压了xlua方案,数值计算指令性能是xlua的651%-720%,其他方面数十倍甚至百倍以上快于xlua方案。
社区版本的HybridCLR除了数值计算跟AOT有较明显差距外,其他方面差距不大。因此对于大多数项目来说,游戏综合性能跟全原生版本差距不大。
商业版本的HybridCLR大幅优化了数值计算性能,性能是社区版本的280%-735%,对性能有严苛要求的开发者可以联系我们商业化服务。
以下是OnePlus 9R ArmV8 实机测试报告,测试代码附录最后。
HybridCLR商业化版本耗时 vs Mono耗时
HybridCLR商业化版本/Mono 性能倍率
HybridCLR商业化版本耗时 vs xlua耗时
HybridCLR商业化版本/xlua 性能倍率
AOT耗时 vs 商业化版本耗时 vs 社区版本耗时 (越小越好)
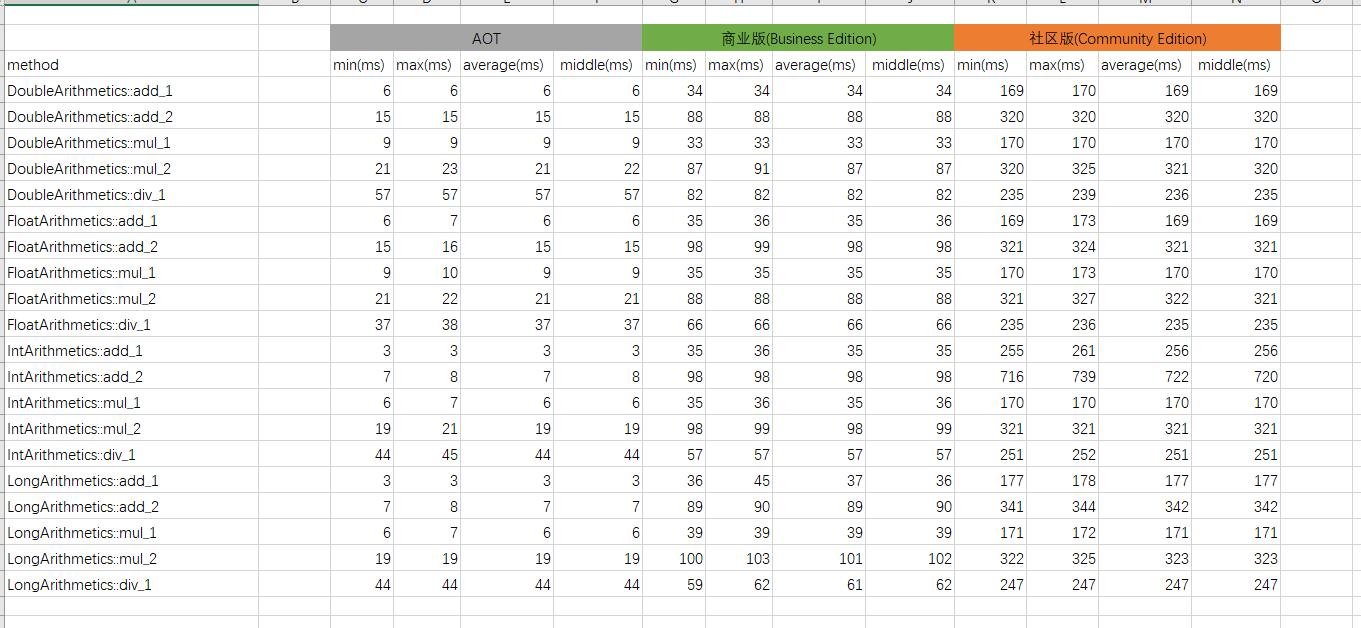
商业化版本耗时/AOT耗时 vs 社区版本耗时/AOT耗时 (越小越好)
AOT版本性能是社区版本的4.1 - 90倍,是商业化版本的1.30 - 12.9倍。
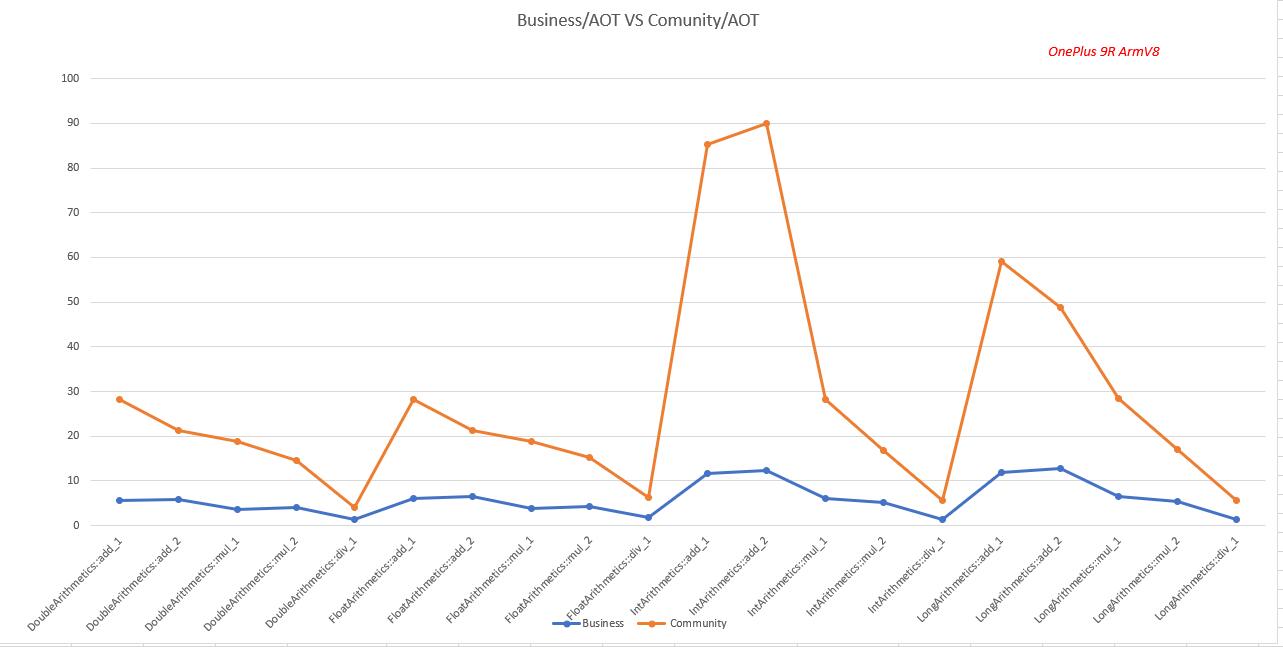
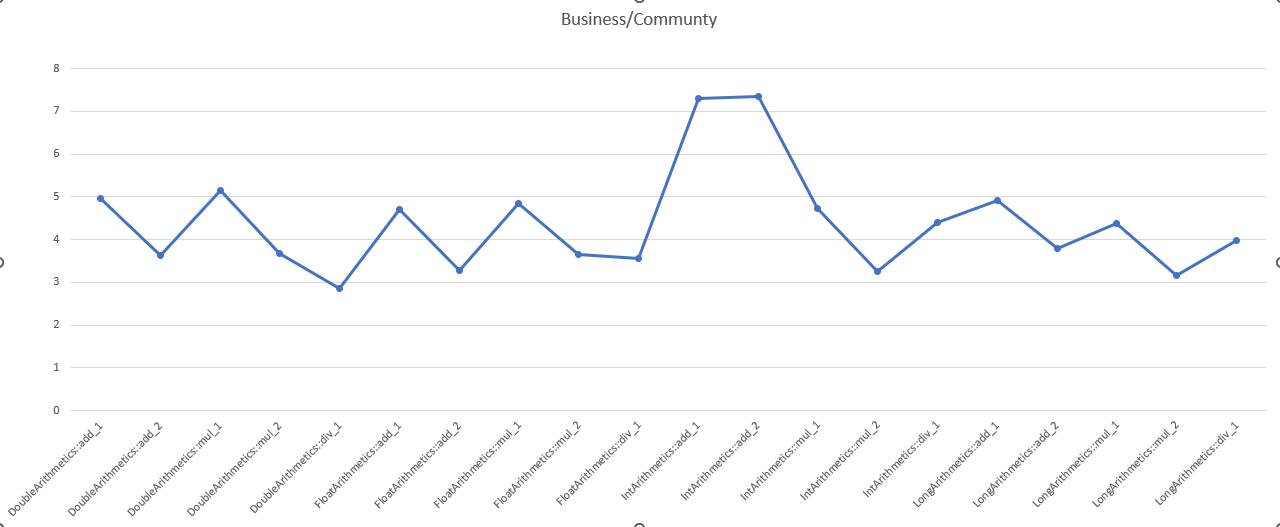
商业化版本性能/社区版本性能 (越大越好)
商业化版本性能是社区版本的2.87-7.35倍。
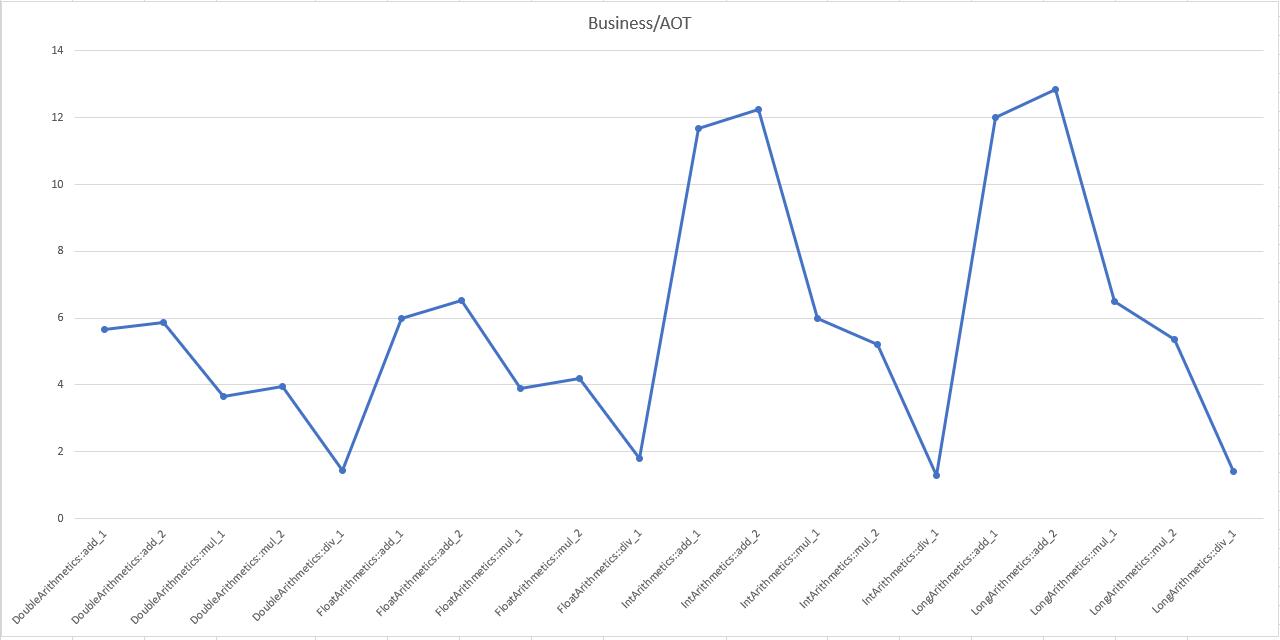
商业化版本耗时/AOT版本耗时 (越小越好)
AOT版本性能是是商业化版本的1.30 - 12.9倍。
原理
由于HybridCLR用C++实现,并且直接与il2cpp运行时无缝集成,可以直接访问运行时底层的数据和各种接口。相比与ILRuntime和Xlua,省去C#层的额外成本,交互成本极大降低。
HybridCLR性能优秀主要来自以下几个方面:
重写的精简高效的metadata解析库
我们没有使用现成的metadata解析库,按照HybridCLR需求实现了一个C++版本的精简高效的metadata 解析库。而其他C#热更新或者hotfix方案均用了Cecil之类的C#库,内存和加载效率差距巨大!
使用寄存器指令集
原始IL字节码是基于栈的指令集,HybridCLR将其转成寄存器指令集,减少了栈维护开销。
直接访问数据栈和执行栈
栈操作是CLI中最常见的操作,几乎所有指令都会涉及到栈操作。由于解释器栈是自己维护的堆内存,CLI对struct的指针操作有限制,如果用C#实现解释器, 则无法直接在解释器栈上操作数据类型,不得不使用使用各种技巧间接达到这个目的。而HybridCLR是C++实现,可以直接操作。
操作struct类型效率相比其他解释器有数倍到数十倍提升。
指令静态特例化
有一些指令如add指令是多功能指令,根据当前栈上的操作数类型来决定最终的操作。HybridCLR为它设计了add_i4、add_i8、add_r4、add_r8这4条指令,翻译指令时
计算出当前堆栈的数据类型,翻译为对应的特例化化指令。节省了运行时判断类型的开销,也节省了运行时维护数据类型的开销。
提前计算好需要resolve的运行时元数据
有些指令如ldtoken、ldstr之类需要运行时将指令中的数据转换为实际地运行时数据。HybridCLR在翻译时直接计算出对应的运行时数据,保存到转换后的指令中, 极大提升了性能
对象成员访问指令实现简单高效
像 v.x = b; 这种对象成员访问指令非常常见,像ILRuntime和xlua由于C#语言限制,不得不通过一个wrap函数调用进行操作。而HybridCLR由于用C++实现,能直接访问
对象的内存数据,通过提前计算字段在对象中的偏移,直接 *(int32_t*)(obj + offset) = b; 就能完成这个访问操作。
相比其他热更新方案数几十倍地提升了效率。
直接支持引用与指针操作,无需通过间接方法
由于CLI的规范限制,在C#中引用只能放到托管栈上,而不能存放到解释器栈上(因为是堆内存)。为了处理 ref int a = ref b; a = 5; 之类的代码,不得不使用非常复杂的
技巧间接地维护这个引用。而HybridCLR使用c++实现,可以直接保存和操作这些数据。
相比其他热更新方案效率极大提升。
元数据统一,创建对象更高效,内存占用也更小
由于元数据统一,可以直接调用il2cpp::vm::Object::New来创建对象,效率跟原生非常接近,而且内存完全相同。相比之下,其他热更新方案使用假类型, 对象臃肿,创建对象的过程更重度复杂。
相比其他热更新方案极大提升了效率。
元数据统一,函数调用方式统一,并且没有PInvoke和ReservePInvoke的额外开销
HybridCLR可以直接调用 由IL函数翻译后的c++函数,没有任何中间环节,而ILRuntime和xlua需要各种复杂的判定和参数转换以及与C#之间PInvoke和ReservePInvoke带来额外大量开销。
HybridCLR与il2cpp AOT部分交互极其轻量高效。不再有性能问题。
额外提供大量instinct函数
像 new Vector{2,3,4}、new string()、Nullable<T>.Value 等等的常用操作,我们直接提供了对应的指令,运行开销甚至低于AOT的实现。
相比其他热更新方案数几十倍地提升了效率。
严格遵循规范,不引入额外不必要成本
由于精心的设计和优化,HybridCLR尽量规避各种不必要的开销。例如执行过程的GC与原生il2cpp及mono完全相同。
其他指令优化技术
其他的优化技术
附录:测试用例代码
商业化版本 vs xlua
- HybridCLR
- xlua
public class AOTForCallFunctions
{
public void Empty()
{
}
public int ReturnInt()
{
return 0;
}
public Vector3 ReturnVector3()
{
return default;
}
public void Func1(int a, int b, int c, int d, int e)
{
}
public void Func2(Vector3 a, Vector3 b, Vector3 c, Vector3 d)
{
}
}
public class BenchmarkTestCases
{
public const int kTestCount = 10000;
/// <summary>
/// 测试简单数值计算
/// </summary>
/// <param name="n"></param>
/// <returns></returns>
[Benchmark]
[Params(kTestCount * 100)]
public int BinOpAdd(int n)
{
int a = 1;
int b = n;
int c = 2;
int d = n;
for (int i = 0; i < n; i++)
{
a = b + c;
b = c + d;
c = d + a;
d = a + b;
a = b + c;
b = c + d;
c = d + a;
d = a + b;
a = b + c;
b = c + d;
c = d + a;
d = a + b;
a = b + c;
b = c + d;
c = d + a;
d = a + b;
a = b + c;
b = c + d;
c = d + a;
d = a + b;
}
return a + b + c + d;
}
/// <summary>
/// 测试复杂数值计算
/// </summary>
/// <param name="cnt"></param>
[Benchmark]
[Params(kTestCount * 100)]
public void BinOpComplex(int cnt)
{
int total = 0;
for (int i = 0; i < cnt; i++)
{
total = total + i - (i - 2) * (i + 3);
total = total + i - (i - 2) * (i + 3);
total = total + i - (i - 2) * (i + 3);
total = total + i - (i - 2) * (i + 3);
total = total + i - (i - 2) * (i + 3);
total = total + i - (i - 2) * (i + 3);
total = total + i - (i - 2) * (i + 3);
total = total + i - (i - 2) * (i + 3);
total = total + i - (i - 2) * (i + 3);
total = total + i - (i - 2) * (i + 3);
}
}
/// <summary>
/// 测试数组操作
/// </summary>
/// <param name="cnt"></param>
[Benchmark]
[Params(kTestCount * 100)]
public int ArrayOp(int cnt)
{
var arr = new int[100];
int k = cnt % 100 + 1;
for (int i = 0; i < cnt; i++)
{
arr[k] = arr[k] + i;
arr[k] = arr[k] + i;
arr[k] = arr[k] + i;
arr[k] = arr[k] + i;
arr[k] = arr[k] + i;
arr[k] = arr[k] + i;
arr[k] = arr[k] + i;
arr[k] = arr[k] + i;
arr[k] = arr[k] + i;
arr[k] = arr[k] + i;
}
return arr[0];
}
/// <summary>
/// 测试Vector3操作
/// </summary>
/// <param name="cnt"></param>
/// <returns></returns>
[Benchmark]
[Params(kTestCount * 10)]
public int VectorOp1(int cnt)
{
float m = 0f;
var v = Vector3.one;
for (var i = 0; i < cnt; i++)
{
m = v.sqrMagnitude;
m = v.sqrMagnitude;
m = v.sqrMagnitude;
m = v.sqrMagnitude;
m = v.sqrMagnitude;
m = v.sqrMagnitude;
m = v.sqrMagnitude;
m = v.sqrMagnitude;
m = v.sqrMagnitude;
m = v.sqrMagnitude;
}
return (int)m;
}
[Benchmark]
[Params(kTestCount * 10)]
public int VectorOp2(int cnt)
{
Vector3 c = default;
var a = new Vector3(1, 2, 3);
var b = new Vector3(4, 5, 6);
for (var i = 0; i < cnt; i++)
{
c = c + a;
c = c + b;
c = c + a;
c = c + b;
c = c + a;
c = c + b;
c = c + a;
c = c + b;
c = c + a;
c = c + b;
}
return (int)c.x;
}
/// <summary>
/// 测试Quaternion操作
/// </summary>
/// <param name="cnt"></param>
/// <returns></returns>
[Benchmark]
[Params(kTestCount * 10)]
public int QuaternionOp(int cnt)
{
for (var i = 0; i < cnt; i++)
{
var q1 = Quaternion.Euler(i, i, i);
var q2 = Quaternion.Slerp(Quaternion.identity, q1, 0.5f);
var q3 = q2.normalized;
var q4 = Quaternion.Lerp(q3, q2, 0.5f);
}
return 0;
}
/// <summary>
/// 测试调用AOT静态成员函数
/// </summary>
/// <param name="cnt"></param>
/// <returns></returns>
[Benchmark]
[Params(kTestCount * 10)]
public int CallAOTStaticMethod(int cnt)
{
float t = 0f;
for (var i = 0; i < cnt; i++)
{
t = Time.deltaTime;
t = Time.deltaTime;
t = Time.deltaTime;
t = Time.deltaTime;
t = Time.deltaTime;
t = Time.deltaTime;
t = Time.deltaTime;
t = Time.deltaTime;
t = Time.deltaTime;
t = Time.deltaTime;
}
return (int)t;
}
/// <summary>
/// 测试调用AOT实例成员函数传int类型参数
/// </summary>
/// <param name="cnt"></param>
/// <returns></returns>
[Benchmark]
[Params(kTestCount * 10)]
public int CallAOTInstanceMethodParamInt(int cnt)
{
var o = new AOTForCallFunctions();
int x = 0;
for (var i = 0; i < cnt; i++)
{
o.Func1(1, 2, 3, 4, 5);
o.Func1(1, 2, 3, 4, 5);
o.Func1(1, 2, 3, 4, 5);
o.Func1(1, 2, 3, 4, 5);
o.Func1(1, 2, 3, 4, 5);
o.Func1(1, 2, 3, 4, 5);
o.Func1(1, 2, 3, 4, 5);
o.Func1(1, 2, 3, 4, 5);
o.Func1(1, 2, 3, 4, 5);
o.Func1(1, 2, 3, 4, 5);
}
return x + 1;
}
/// <summary>
/// 测试调用AOT实例成员函数传Vector3类型参数
/// </summary>
/// <param name="cnt"></param>
/// <returns></returns>
[Benchmark]
[Params(kTestCount * 10)]
public int CallAOTInstanceMethodParamVector3(int cnt)
{
var o = new AOTForCallFunctions();
Vector3 a = Vector3.one;
Vector3 b = Vector3.one;
for (var i = 0; i < cnt; i++)
{
o.Func2(a, b, a, b);
o.Func2(a, b, a, b);
o.Func2(a, b, a, b);
o.Func2(a, b, a, b);
o.Func2(a, b, a, b);
o.Func2(a, b, a, b);
o.Func2(a, b, a, b);
o.Func2(a, b, a, b);
o.Func2(a, b, a, b);
o.Func2(a, b, a, b);
}
return 0;
}
/// <summary>
/// 测试调用AOT实例成员函数,返回值为int
/// </summary>
/// <param name="cnt"></param>
/// <returns></returns>
[Benchmark]
[Params(kTestCount * 10)]
public int CallAOTInstanceMethodReturn1(int cnt)
{
var o = new AOTForCallFunctions();
int x = 0;
for (var i = 0; i < cnt; i++)
{
x = o.ReturnInt();
x = o.ReturnInt();
x = o.ReturnInt();
x = o.ReturnInt();
x = o.ReturnInt();
x = o.ReturnInt();
x = o.ReturnInt();
x = o.ReturnInt();
x = o.ReturnInt();
x = o.ReturnInt();
}
return x + 1;
}
/// <summary>
/// 测试调用AOT实例成员函数,返回值为Vector3
/// </summary>
/// <param name="cnt"></param>
/// <returns></returns>
[Benchmark]
[Params(kTestCount * 10)]
public int CallAOTInstanceMethodReturnVector3(int cnt)
{
var o = new AOTForCallFunctions();
Vector3 x = default;
for (var i = 0; i < cnt; i++)
{
x = o.ReturnVector3();
x = o.ReturnVector3();
x = o.ReturnVector3();
x = o.ReturnVector3();
x = o.ReturnVector3();
x = o.ReturnVector3();
x = o.ReturnVector3();
x = o.ReturnVector3();
x = o.ReturnVector3();
x = o.ReturnVector3();
}
return (int)x.x;
}
/// <summary>
/// 测试GameObject创建和销毁操作
/// </summary>
/// <param name="cnt"></param>
[Benchmark]
[Params(kTestCount)]
public void GameObjectCreateAndDestroy(int cnt)
{
for (var i = 0; i < cnt; i++)
{
var go = new GameObject("t");
Object.Destroy(go);
}
}
/// <summary>
/// 测试 Transform操作
/// </summary>
/// <param name="cnt"></param>
[Benchmark]
[Params(kTestCount * 10)]
public void SetTransformPosition(int cnt)
{
var go = new GameObject();
Vector3 v = Vector3.one;
for (var i = 0; i < cnt; i++)
{
go.transform.position = v;
go.transform.position = v;
go.transform.position = v;
go.transform.position = v;
go.transform.position = v;
go.transform.position = v;
go.transform.position = v;
go.transform.position = v;
go.transform.position = v;
go.transform.position = v;
}
Object.Destroy(go);
}
}
function BinOpAdd(cnt)
local a = 1;
local b = cnt;
local c = cnt;
local d = cnt;
for i = 1, cnt do
a = b + c;
b = c + d;
c = d + a;
d = a + b;
a = b + c;
b = c + d;
c = d + a;
d = a + b;
a = b + c;
b = c + d;
c = d + a;
d = a + b;
a = b + c;
b = c + d;
c = d + a;
d = a + b;
a = b + c;
b = c + d;
c = d + a;
d = a + b;
end
return a + b + c + d
end
function BinOpComplex(cnt)
local total = 0;
for i = 1, cnt do
total = total + i - (i - 2) * (i + 3);
total = total + i - (i - 2) * (i + 3);
total = total + i - (i - 2) * (i + 3);
total = total + i - (i - 2) * (i + 3);
total = total + i - (i - 2) * (i + 3);
total = total + i - (i - 2) * (i + 3);
total = total + i - (i - 2) * (i + 3);
total = total + i - (i - 2) * (i + 3);
total = total + i - (i - 2) * (i + 3);
total = total + i - (i - 2) * (i + 3);
end
return total
end
function ArrayOp(cnt)
local arr = {}
for i = 0, 100 do
arr[i] = 0
end
local k = cnt % 100 + 1;
for i = 1, cnt do
arr[k] = arr[k] + i;
arr[k] = arr[k] + i;
arr[k] = arr[k] + i;
arr[k] = arr[k] + i;
arr[k] = arr[k] + i;
arr[k] = arr[k] + i;
arr[k] = arr[k] + i;
arr[k] = arr[k] + i;
arr[k] = arr[k] + i;
arr[k] = arr[k] + i;
end
return arr[0]
end
function VectorOp1(cnt)
local m = 0
local v = CS.UnityEngine.Vector3.one;
for i = 1, cnt do
m = v.sqrMagnitude;
m = v.sqrMagnitude;
m = v.sqrMagnitude;
m = v.sqrMagnitude;
m = v.sqrMagnitude;
m = v.sqrMagnitude;
m = v.sqrMagnitude;
m = v.sqrMagnitude;
m = v.sqrMagnitude;
m = v.sqrMagnitude;
end
return m;
end
function VectorOp2(cnt)
local c = CS.UnityEngine.Vector3.one;
local a = CS.UnityEngine.Vector3(1, 2, 3);
local b = CS.UnityEngine.Vector3(4, 5, 6);
for i = 1, cnt do
c = c + a;
c = c + b;
c = c + a;
c = c + b;
c = c + a;
c = c + b;
c = c + a;
c = c + b;
c = c + a;
c = c + b;
end
return c.x
end
local Quaternion = CS.UnityEngine.Quaternion
function QuaternionOp(cnt)
for i = 1, cnt do
local q1 = Quaternion.Euler(i, i, i);
local q2 = Quaternion.Slerp(Quaternion.identity, q1, 0.5);
local q3 = q2.normalized;
local q4 = Quaternion.Lerp(q3, q2, 0.5);
end
return 0;
end
function CallAOTStaticMethod(cnt)
local Time = CS.UnityEngine.Time
local t
for i = 1, cnt do
t = Time.deltaTime
end
return t
end
function CallAOTInstanceMethodParamInt(cnt)
local o = CS.AOTTypes.AOTForCallFunctions();
for i = 1, cnt do
o:Func1(1, 2, 3, 4, 5);
o:Func1(1, 2, 3, 4, 5);
o:Func1(1, 2, 3, 4, 5);
o:Func1(1, 2, 3, 4, 5);
o:Func1(1, 2, 3, 4, 5);
o:Func1(1, 2, 3, 4, 5);
o:Func1(1, 2, 3, 4, 5);
o:Func1(1, 2, 3, 4, 5);
o:Func1(1, 2, 3, 4, 5);
o:Func1(1, 2, 3, 4, 5);
end
end
function CallAOTInstanceMethodParamVector3(cnt)
local o = CS.AOTTypes.AOTForCallFunctions();
local a = CS.UnityEngine.Vector3.one;
local b = CS.UnityEngine.Vector3.one;
for i = 1, cnt do
o:Func2(a, b, a, b)
o:Func2(a, b, a, b)
o:Func2(a, b, a, b)
o:Func2(a, b, a, b)
o:Func2(a, b, a, b)
o:Func2(a, b, a, b)
o:Func2(a, b, a, b)
o:Func2(a, b, a, b)
o:Func2(a, b, a, b)
o:Func2(a, b, a, b)
end
end
function CallAOTInstanceMethodReturn1(cnt)
local o = CS.AOTTypes.AOTForCallFunctions();
local x = 0;
for i = 1, cnt do
x = o:ReturnInt();
x = o:ReturnInt();
x = o:ReturnInt();
x = o:ReturnInt();
x = o:ReturnInt();
x = o:ReturnInt();
x = o:ReturnInt();
x = o:ReturnInt();
x = o:ReturnInt();
x = o:ReturnInt();
end
return x + 1;
end
function CallAOTInstanceMethodReturnVector3(cnt)
local o = CS.AOTTypes.AOTForCallFunctions();
local x
for i = 1, cnt do
x = o:ReturnVector3();
x = o:ReturnVector3();
x = o:ReturnVector3();
x = o:ReturnVector3();
x = o:ReturnVector3();
x = o:ReturnVector3();
x = o:ReturnVector3();
x = o:ReturnVector3();
x = o:ReturnVector3();
x = o:ReturnVector3();
end
return x;
end
function GameObjectCreateAndDestroy(cnt)
for i = 1, cnt do
local go = CS.UnityEngine.GameObject("t")
CS.UnityEngine.Object.Destroy(go)
end
end
function SetTransformPosition(cnt)
local go = CS.UnityEngine.GameObject("t")
local v = CS.UnityEngine.Vector3.one;
for i = 1, cnt do
go.transform.position = v;
go.transform.position = v;
go.transform.position = v;
go.transform.position = v;
go.transform.position = v;
go.transform.position = v;
go.transform.position = v;
go.transform.position = v;
go.transform.position = v;
go.transform.position = v;
end
CS.UnityEngine.Object.Destroy(go)
end
AOT vs 社区版 vs 商业化版本 vs Mono
public class LongArithmetics
{
[Benchmark]
[Params(1000000)]
public long add_1(long n)
{
long a = 1;
long b = n;
long c = 2;
long d = n;
for(long i = 0; i < n; i++)
{
a = b + c;
b = c + d;
c = d + a;
d = a + b;
a = b + c;
b = c + d;
c = d + a;
d = a + b;
a = b + c;
b = c + d;
c = d + a;
d = a + b;
a = b + c;
b = c + d;
c = d + a;
d = a + b;
a = b + c;
b = c + d;
c = d + a;
d = a + b;
}
return a + b + c + d;
}
[Benchmark]
[Params(1000000)]
public long add_2(long n)
{
long a = 1;
long b = n;
long c = 2;
long d = n;
long e = 3;
for (long i = 0; i < n; i++)
{
a = b + c + d + e;
b = c + d + e + a;
c = d + e + a + b;
d = e + a + b + c;
e = a + b + c + d;
a = b + c + d + e;
b = c + d + e + a;
c = d + e + a + b;
d = e + a + b + c;
e = a + b + c + d;
a = b + c + d + e;
b = c + d + e + a;
c = d + e + a + b;
d = e + a + b + c;
e = a + b + c + d;
a = b + c + d + e;
b = c + d + e + a;
c = d + e + a + b;
d = e + a + b + c;
e = a + b + c + d;
}
return a + b + c + d;
}
[Benchmark]
[Params(1000000)]
public long mul_1(long n)
{
long a = 1;
long b = n;
long c = 2;
long d = n;
for (long i = 0; i < n; i++)
{
a = b * c;
b = c * d;
c = d * a;
d = a * b;
a = b * c;
b = c * d;
c = d * a;
d = a * b;
a = b * c;
b = c * d;
c = d * a;
d = a * b;
a = b * c;
b = c * d;
c = d * a;
d = a * b;
a = b * c;
b = c * d;
c = d * a;
d = a * b;
}
return a + b + c + d;
}
[Benchmark]
[Params(1000000)]
public long mul_2(long n)
{
long a = 1;
long b = n;
long c = 2;
long d = n;
long e = 3;
for (long i = 0; i < n; i++)
{
a = b * c * d * e;
b = c * d * e * a;
c = d * e * a * b;
d = e * a * b * c;
e = a * b * c * d;
a = b * c * d * e;
b = c * d * e * a;
c = d * e * a * b;
d = e * a * b * c;
e = a * b * c * d;
a = b * c * d * e;
b = c * d * e * a;
c = d * e * a * b;
d = e * a * b * c;
e = a * b * c * d;
a = b * c * d * e;
b = c * d * e * a;
c = d * e * a * b;
d = e * a * b * c;
e = a * b * c * d;
}
return a + b + c + d;
}
[Benchmark]
[Params(1000000)]
public long div_1(long n)
{
long a = 1;
long b = n;
long c = 2;
long d = n;
for (long i = 0; i < n; i++)
{
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
a = a / n + 1;
}
return a + b + c + d;
}
public class IntArithmetics
{
[Benchmark]
[Params(1000000)]
public int add_1(int n)
{
int a = 1;
int b = n;
int c = 2;
int d = n;
for(int i = 0; i < n; i++)
{
a = b + c;
b = c + d;
c = d + a;
d = a + b;
a = b + c;
b = c + d;
c = d + a;
d = a + b;
a = b + c;
b = c + d;
c = d + a;
d = a + b;
a = b + c;
b = c + d;
c = d + a;
d = a + b;
a = b + c;
b = c + d;
c = d + a;
d = a + b;
}
return a + b + c + d;
}
[Benchmark]
[Params(1000000)]
public int add_2(int n)
{
int a = 1;
int b = n;
int c = 2;
int d = n;
int e = 3;
for (int i = 0; i < n; i++)
{
a = b + c + d + e;
b = c + d + e + a;
c = d + e + a + b;
d = e + a + b + c;
e = a + b + c + d;
a = b + c + d + e;
b = c + d + e + a;
c = d + e + a + b;
d = e + a + b + c;
e = a + b + c + d;
a = b + c + d + e;
b = c + d + e + a;
c = d + e + a + b;
d = e + a + b + c;
e = a + b + c + d;
a = b + c + d + e;
b = c + d + e + a;
c = d + e + a + b;
d = e + a + b + c;
e = a + b + c + d;
}
return a + b + c + d;
}
[Benchmark]
[Params(1000000)]
public int mul_1(int n)
{
int a = 1;
int b = n;
int c = 2;
int d = n;
for (int i = 0; i < n; i++)
{
a = b * c;
b = c * d;
c = d * a;
d = a * b;
a = b * c;
b = c * d;
c = d * a;
d = a * b;
a = b * c;
b = c * d;
c = d * a;
d = a * b;
a = b * c;
b = c * d;
c = d * a;
d = a * b;
a = b * c;
b = c * d;
c = d * a;
d = a * b;
}
return a + b + c + d;
}
[Benchmark]
[Params(1000000)]
public int mul_2(int n)
{
int a = 1;
int b = n;
int c = 2;
int d = n;
int e = 3;
for (int i = 0; i < n; i++)
{
a = b * c * d * e;
b = c * d * e * a;
c = d * e * a * b;
d = e * a * b * c;
e = a * b * c * d;
a = b * c * d * e;
b = c * d * e * a;
c = d * e * a * b;
d = e * a * b * c;
e = a * b * c * d;
a = b * c * d * e;
b = c * d * e * a;
c = d * e * a * b;
d = e * a * b * c;
e = a * b * c * d;
a = b * c * d * e;
b = c * d * e * a;
c = d * e * a * b;
d = e * a * b * c;
e = a * b * c * d;
}
return a + b + c + d;
}
[Benchmark]
[Params(1000000)]
public int div_1(int n)
{
int a = 1;
int b = n;
int c = 2;
int d = n;
for (int i = 0; i < n; i++)
{
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
a = a / n + 1;
}
return a + b + c + d;
}
}
public class FloatArithmetics
{
[Benchmark]
[Params(1000000)]
public float add_1(int n)
{
float a = 1;
float b = n;
float c = 2;
float d = n;
for(int i = 0; i < n; i++)
{
a = b + c;
b = c + d;
c = d + a;
d = a + b;
a = b + c;
b = c + d;
c = d + a;
d = a + b;
a = b + c;
b = c + d;
c = d + a;
d = a + b;
a = b + c;
b = c + d;
c = d + a;
d = a + b;
a = b + c;
b = c + d;
c = d + a;
d = a + b;
}
return a + b + c + d;
}
[Benchmark]
[Params(1000000)]
public float add_2(int n)
{
float a = 1;
float b = n;
float c = 2;
float d = n;
float e = 3;
for (int i = 0; i < n; i++)
{
a = b + c + d + e;
b = c + d + e + a;
c = d + e + a + b;
d = e + a + b + c;
e = a + b + c + d;
a = b + c + d + e;
b = c + d + e + a;
c = d + e + a + b;
d = e + a + b + c;
e = a + b + c + d;
a = b + c + d + e;
b = c + d + e + a;
c = d + e + a + b;
d = e + a + b + c;
e = a + b + c + d;
a = b + c + d + e;
b = c + d + e + a;
c = d + e + a + b;
d = e + a + b + c;
e = a + b + c + d;
}
return a + b + c + d;
}
[Benchmark]
[Params(1000000)]
public float mul_1(int n)
{
float a = 1;
float b = n;
float c = 2;
float d = n;
for (int i = 0; i < n; i++)
{
a = b * c;
b = c * d;
c = d * a;
d = a * b;
a = b * c;
b = c * d;
c = d * a;
d = a * b;
a = b * c;
b = c * d;
c = d * a;
d = a * b;
a = b * c;
b = c * d;
c = d * a;
d = a * b;
a = b * c;
b = c * d;
c = d * a;
d = a * b;
}
return a + b + c + d;
}
[Benchmark]
[Params(1000000)]
public float mul_2(int n)
{
float a = 1;
float b = n;
float c = 2;
float d = n;
float e = 3;
for (int i = 0; i < n; i++)
{
a = b * c * d * e;
b = c * d * e * a;
c = d * e * a * b;
d = e * a * b * c;
e = a * b * c * d;
a = b * c * d * e;
b = c * d * e * a;
c = d * e * a * b;
d = e * a * b * c;
e = a * b * c * d;
a = b * c * d * e;
b = c * d * e * a;
c = d * e * a * b;
d = e * a * b * c;
e = a * b * c * d;
a = b * c * d * e;
b = c * d * e * a;
c = d * e * a * b;
d = e * a * b * c;
e = a * b * c * d;
}
return a + b + c + d;
}
[Benchmark]
[Params(1000000)]
public float div_1(int n)
{
float a = 1;
float b = n;
float c = 2;
float d = n;
for (int i = 0; i < n; i++)
{
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
a = a / n + 1;
}
return a + b + c + d;
}
}
public class DoubleArithmetics
{
[Benchmark]
[Params(1000000)]
public double add_1(int n)
{
double a = 1;
double b = n;
double c = 2;
double d = n;
for (int i = 0; i < n; i++)
{
a = b + c;
b = c + d;
c = d + a;
d = a + b;
a = b + c;
b = c + d;
c = d + a;
d = a + b;
a = b + c;
b = c + d;
c = d + a;
d = a + b;
a = b + c;
b = c + d;
c = d + a;
d = a + b;
a = b + c;
b = c + d;
c = d + a;
d = a + b;
}
return a + b + c + d;
}
[Benchmark]
[Params(1000000)]
public double add_2(int n)
{
double a = 1;
double b = n;
double c = 2;
double d = n;
double e = 3;
for (int i = 0; i < n; i++)
{
a = b + c + d + e;
b = c + d + e + a;
c = d + e + a + b;
d = e + a + b + c;
e = a + b + c + d;
a = b + c + d + e;
b = c + d + e + a;
c = d + e + a + b;
d = e + a + b + c;
e = a + b + c + d;
a = b + c + d + e;
b = c + d + e + a;
c = d + e + a + b;
d = e + a + b + c;
e = a + b + c + d;
a = b + c + d + e;
b = c + d + e + a;
c = d + e + a + b;
d = e + a + b + c;
e = a + b + c + d;
}
return a + b + c + d;
}
[Benchmark]
[Params(1000000)]
public double mul_1(int n)
{
double a = 1;
double b = n;
double c = 2;
double d = n;
for (int i = 0; i < n; i++)
{
a = b * c;
b = c * d;
c = d * a;
d = a * b;
a = b * c;
b = c * d;
c = d * a;
d = a * b;
a = b * c;
b = c * d;
c = d * a;
d = a * b;
a = b * c;
b = c * d;
c = d * a;
d = a * b;
a = b * c;
b = c * d;
c = d * a;
d = a * b;
}
return a + b + c + d;
}
[Benchmark]
[Params(1000000)]
public double mul_2(int n)
{
double a = 1;
double b = n;
double c = 2;
double d = n;
double e = 3;
for (int i = 0; i < n; i++)
{
a = b * c * d * e;
b = c * d * e * a;
c = d * e * a * b;
d = e * a * b * c;
e = a * b * c * d;
a = b * c * d * e;
b = c * d * e * a;
c = d * e * a * b;
d = e * a * b * c;
e = a * b * c * d;
a = b * c * d * e;
b = c * d * e * a;
c = d * e * a * b;
d = e * a * b * c;
e = a * b * c * d;
a = b * c * d * e;
b = c * d * e * a;
c = d * e * a * b;
d = e * a * b * c;
e = a * b * c * d;
}
return a + b + c + d;
}
[Benchmark]
[Params(1000000)]
public double div_1(int n)
{
double a = 1;
double b = n;
double c = 2;
double d = n;
for (int i = 0; i < n; i++)
{
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
b = c / a;
c = d / a;
d = b / a;
a = a / n + 1;
}
return a + b + c + d;
}
}